
Crawling tools, such as Screaming Frog or Deepcrawl, are fantastic ways to analyse large websites. A little while ago, I wrote about some of the custom extraction examples that I had been playing with gather data about ecommerce sites. Since I was still learning at this point, I mainly used Regex examples as I had worked with this in the past. At the time, I had used Xpath but was not confident enough to be able to use it to its full potential. Now that I have had more practice, I would like to share my knowledge with you all.
[do_widget id=custom_html-3]
What is a custom extraction?
Crawling tools like Screaming Frog obtain lots of data about each page, such as the title, H1 or meta description. Each of these pieces of information is called an extraction. However, sometimes we need to extract information on a page which isn’t obtained by default. Examples could include price, stock availability or product description. You can request crawlers to obtain this information by specifying the correct Xpath or regex. In Screaming Frog, you can do this by going to ‘Configuration>Custom>Extraction’ and find the results in the Custom tab, after selecting Extraction from the filter drop down. To make these extractions work, you will need to choose the correct extraction type from the drop down on the right.
Basic Xpath Structure
Many people who start using Xpath get their examples by copy and pasting from Chrome’s Developer Tools. To do this, you will need to inspect element then right click on the required HMTL and select ‘Copy > Xpath’ like in the screenshot below:
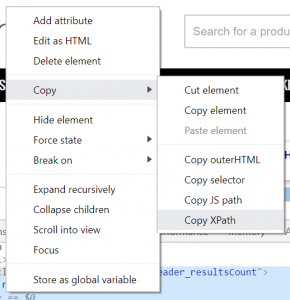
An example of this Xpath is as follows:
//*[@id=”home”]/div[1]/section/div/section/section/div[1]/main/div[1]/div[1]/p
To summarise what this means (deep breath), its the paragraph thats within the 1st div thats within the 1st div thats within the <main> tag within the 1st div within the <section> tag within the <section> tag within the div thats within the <section> tag within the 1st div thats within a tag with the id of “home”.
Apart from being a bit of a mouthful, the main issue with this method is that it requires every page you’re crawling to have exactly the same HTML structure. If there are any variations then the custom extractions will find nothing.
The aim of this article is to give a better understanding of how to create them so that simple, robust Xpaths can be created which can be used in bulk on any website.
Let’s break it down
I’ll start with one of the most common examples, lets imagine we want to extract the contents of a div with a particular class, such as:
<div class=”div-class-name”><p>Example</p></div>
The Xpath for this will be:
//div[@class=’div-class-name’]/p
The parent HTML tag starts on the left, and the child tags are separated by a forward slash. You can also specify to only extraction information from tags with a particlar attribute, such as ‘rel‘ or ‘alt‘. In this case, the attribute we are interested in is ‘class‘, which is the most common example you will come across.
Xpath for elements with multiple classes
Occasionally, you will want to extract an element which has multiple classes. Such an example would look like this:
<div class=”class1 class2″><p>Example</p></div>
In this instance, the above Xpath won’t work as it can only exactly match a single value of an attribute. To get around this, we will need to use the contains() function and the and operator. Rather than looking up the exact value of the class, it will search for a specific string within it. Therefore, the Xpath for the above example will be:
//div[contains(@class, ‘class1’) and contains(@class, ‘class2’)]/p
This will search for a div where the class value contains both class1 and class2.
Extracting the Nth instance
Sometimes the class value you are looking for will appear several times on a page, but you are only interested in the 1st or 2nd instance, such as the first product that appears on each category page. Such an example might look like this:
<div class=”div-class-name”>Example 1</div>
<div class=”div-class-name”>Example 2</div>
In this case, the Xpath would look like this:
(//div[@class=’div-class-name’])[1]
Where the [1] refers to the first instance (“Example 1”). If was changed to [2] then the extracted value will be “Example 2”.
Trimming white space
Sometimes, the extracted values will contain white space before and after the text you are looking to extract. This can be problematic if you want to export to a CSV. To fix this issue, you can use the normalize-space() function. In Screaming Frog, you will need to select ‘function value’ as your extraction type. Simply put it around the Xpath like this:
normalize-space(//div[@class=”category-description”])
Counting instances
In Screaming Frog, the Custom Search tool already allows you to count the amount of times a specific string appears in the source code. However, this might not always do the trick if elements are formatted differently. In Screaming Frog, you will need to select ‘function value’ as your extraction type. For this, the count() function can be used like this:
count(//div[contains(@class ,’product-‘)])
The above Xpath will count every div where the class value contains ‘product-‘.
[do_widget id=custom_html-3]
All hail the double slash!
Imagine you want to get all the outgoing link urls for an article. Using the above advice above, the appropriate Xpath would be something like:
//div[@class=’article-content’]/a/@href
However, this would not catch any links that appear within child elements of the main article div, such as <span> or <li>. Therefore, we would need to use a double slash, as follows:
//div[@class=’article-content’]//a/@href
The double slash will look for all the requested elements within the previously defined tag, regardless of which other tags they appear in.
Working examples
To help you understnad these a little bit further, lets try a couple of really useful examples which can really help with your website analysis.
Helping with Link audits
Link audits are one of the most tedious tasks in SEO. It involves looking through every link to the site to identify any which are unnatural or could suggest negative SEO by a competitor. However, custom extractions using Xpath could speed this up a little.
For example, not every page that is reported to contain a link to you will still be valid. So the first step is to rule out the ones that don’t. To do this, use the following Xpath:
//a[contains(@href, ‘yourwebsite.com’)]
This will give you a list of only the urls which contain <a> tags which link to yourwebsite.com. All of the others can then be discarded… kinda. (This will not identify Javascript links, which Google has said in the past do not pass any signals).
You can take this a step further and also rule out nofollow links. Since they do no pass authority, they do not need to be audited. Use the following Xpath to get a list of all the links containing rel=”nofollow”:
//a[contains(@href, ‘example.co.uk’)]/@rel
These links can then be removed from your audit.
Be careful though, websites can change over time. If a site is really bad, like REALLY bad, (eg, submitseolink.info) you should probably disavow it anyway.
Internal linking opportunities
For this little gem, I have Dan Brooks (@seodanbrooks) on Twitter to thank for. Recently, he posted the following tweet:
Very useful XPath to use with @screamingfrog to identify internal linking opportunities in mass!
Google Sheet template & guide to follow shortly! 🤓🐸🔍 #SEO pic.twitter.com/vcjmVoPLnB
— Dan Brooks 🤓🔍 (@seodanbrooks) August 1, 2019
If you want to give this a go, you can use the following Xpath:
//p[contains(text(),’keyword’)]
This will search for any paragraphs which contain the keyword you would like to use as anchor text to your money page. Very useful if you want to search 100s of blog posts. You can take this a step further and only return paragraphs which are not already linking to your target page by using th not() function as follows:
//a[not(contains(@href, ‘example.co.uk/target-url’))] and p[contains(text(),’keyword’)]
(NOTE: This has not been tested, if you can’t get it to work then get in touch and I’ll see what I can do.)
So there we have it. Hopefully, you should all now be experts in creating Xpath for any custom extraction. To help you further, I have created a little cheat sheet here.
Whilst you’re here, why not check out our article on how to find internal link opportunities.
[do_widget id=custom_html-3]
Read whole article but it seems as a whole package of insightful journey of customer path.
It’s far too impressive fir being your first piece ✔️
Thanks keep sharing!!